ScribusGenerator
Mail-Merge-like extension to Scribus, to generate Scribus and pdf documents automatically from external data (spreadsheet, database and more).
![]() Scribus Generator: Create beautiful documents with data.
Scribus Generator: Create beautiful documents with data.
Open source high-quality pdf template and mail-merge alternative. Your imagination is the limit for creating beautiful yearbooks, personalised weedings invitations, game cards decks, clubs rosters, art or work portfolio and many more.
What is Scribus Generator?
Scribus comes with a broad set of page layout features and functionality. One feature missing is to replace text with data dynamically. This kind of feature you may already know as the typical mail merge functionality in your preferred office application.
Scribus Generator provides this functionality. It allows you to:
- replace texts and images dynamically
- change object colors, position, text font or size dynamically
- generate separate PDF (or Scribus) files for each data entry, or a single file from all your data
- work directly in Scribus with a nice user interface, or from the command line
- use any data source (Excel, OpenOffice, MySQL, Notepad, …) that can export to CSV.
- and much more…
Generally speaking, Scribus Generator replaces text with data to automatically generate files (e.g. SLA, PDF). It has been originally written by Ekkehard Will and further extended by Berteh.
A short how to video introduces this Scribus Generator. 6 first minutes for the basic overview, 12 last for some more advanced features.
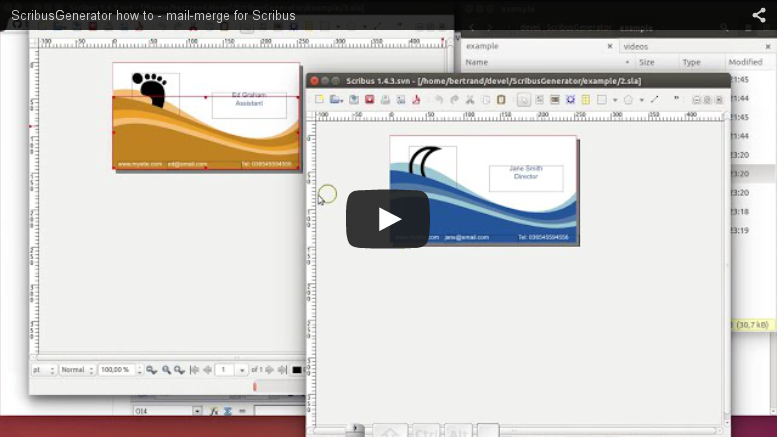
How to install Scribus Generator ?
For recent Scribus (1.7.1, 1.6.x, 1.5.6+,…): download the latest ScribusGenerator version. Most recently added features include a GUI for MacOS users.
For legacy Scribus 1.4.x to 1.5.5: Download the older ScribusGenerator archived script. It is not supported any longer, but just works with older (python2-based) systems.
Uncompress the script anywhere on the local machine in a folder your user can write to. Scribus Generator can then be started by choosing the script (ScribusGenerator.py) within the dialog: «Scribus → Script → Execute Script», or from the command line.
How to use Scribus Generator
Create your Scribus “template” file
Create and design your Scribus file as any other. At the positions where you need to replace text with data, just add %VAR_name% where name is the column your data file. Check out our gallery of examples to see what others did. Any existing Scribus file can be used as template.
You can place the variable at any position within a Text Frame. Apply all format and style to the variable that you wish to apply to the final text.
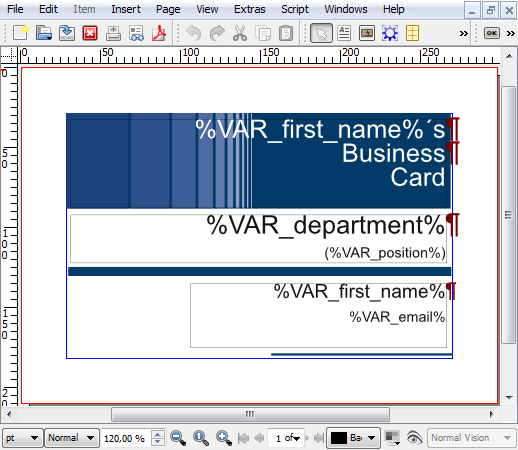
If you wish to generate one page (or many) for each data entry you’re done, congratulations ! If you would rather display many data entries on a single page simply add the text %SG_NEXT-RECORD% before each entry but the first: ScribusGenerator will automatically load the new data record as soon as it detects this token.
Create your (csv) Data File
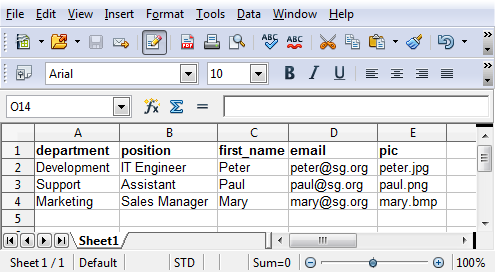
Scribus Generator expects a CSV file (Comma Separated Values), which is very simple to create with a standard spread sheet editor (such as LibreOffice, Excel or GoogleDoc): enter the data and save/export as CSV. Just make sure your CSV file is encoded in UTF-8 to have a full character set (accents, braille, math, cyrillic, symbols,…).
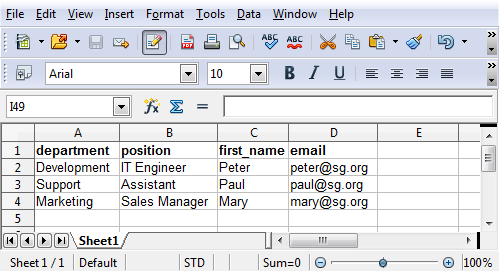
It is important to make sure the columns have the same name as the variables (%VAR_name%) you reference in the Scribus template file you have designed.
We recommend saving in UTF-8 encoding to enable the full set of accentuated characters, chinese, cyrillic, math symbols, arrows, braille, symbols and many more. Simply copy-paste those for which you lack a keyboard combination.
To export well-formated CSV in UTF-8 encoding is easy as pie with OpenOffice or LibreOffice Calc, less so with Excel. If you are using Microsoft’s Excel you may be interested in this free add-in that provides good export/import features: http://www.csvio.net/
CSV files can easily be generated from many existing data sources (incl. enterprise-grade ETL platforms, most databases like MySQL, PostgreSQL, SQLite3 and more, ), see our wiki page for using other data sources
Run the Generator Script - Settings (Linux and Windows)
Run the script via the menu: Script > execute Script and launch ScribusGenerator.py.
In the script dialog you can configure the input and output settings for Scribus Generator.
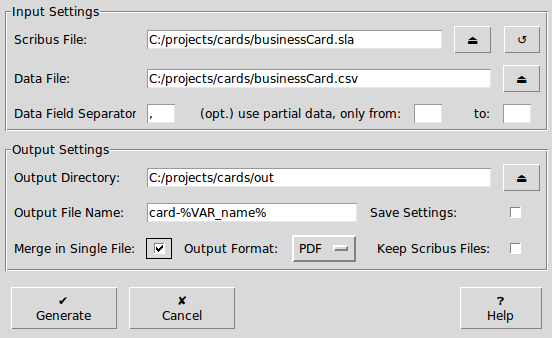
| Input Setting | explanation |
|---|---|
| Scribus File | Choose the Scribus File containing the variables to replace. Click ⏏ to open a file explorer, and ↺ to load the Scribus Generator settings from that file. |
| Data File | Choose the Data File containing the comma separated values. Click ⏏ to open a file explorer. |
| Data Field Separator | Character that delimitates data field in your CSV file, comma (,) by default. |
| From - To | To run Scribus Generator on a subset of your data mention the starting and/or last lines of this subset, not counting the header line. Simply leave empty to generate from the beginning (or to the last) data entry. |
| Output Setting | explanation |
|---|---|
| Output Directory | Choose the path to an existing directory where to save the result. Click ⏏ to open a file explorer. |
| Output File Name | You can use the same variables as defined in the Scribus File/Data File. You can also use variables and the dedicated %VAR_COUNT% index reflecting the row position in the Data File. It is used by default if you leave the field empty. |
| Save Settings | Store the current Scribus Generator settings in the source SLA file, for future use. |
| Merge in Single File | Select to generate a single output (SLA and/or PDF) file that combines all data rows. |
| Output Format | Choose the Output Format of the generated files, either PDF or Scribus. |
| Keep Scribus Files | Select to keep the generated Scribus Files. Otherwise they will be deleted after pdf generation. This option has no effect if you choose Scribus output format. |
Additional (more technical) options can be set to tailor the automatic recording of Scribus Generators actions in your system by editing the logging.conf file. You may, for instance, want to move the location of the log file (scribusGenerator.log by default) to a directory that does not need admin rights to edit in Windows (C:\tmp\scribusGenerator.log), or replace file-logging with your default system logger (SysLogHandler in Linux, NTEventLogHandler on Windows). All settings (and more) are described in the Python logging documentation.
Run the Generator Script - Settings (MacOS)
Run the appropriate script via the menu: Script > execute Script and launch ScribusGeneratorMac.py.
The Mac version of the script uses the Scribus Plugin API which has support for a very limited GUI, so you will instead have to enter and confirm your settings in a series of dialog boxes:
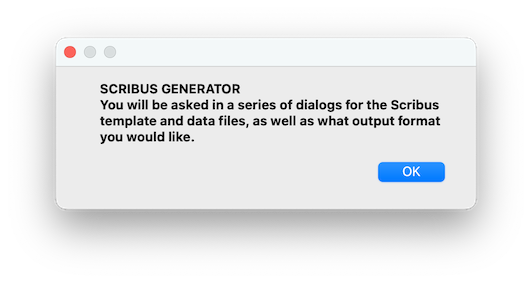
This dialog just lets you know that Scribus Generator is now running, and tells you that you will be presented with a series of dialogs collecting the needed input infos. Kindly follow the very detailed ScribusGeneratorMac guide for a step-by-step walktrough. Many thanks to kmcreative for this nice addition to ScribusGenerator.
Mac users can also use the command line version of Scribus Generator, from a terminal window.
Dynamic Images
Images references can also be dynamically modified with Scribus Generator. See the screencast video @6:10.
All images supported by Scribus can be used. However, to work with ScribusGenerator, they must all be located in a single folder containing all images. This folder can be located anywhere on your PC. Duplicate any image in this folder and rename it %VAR_pic% (and similarly for any other variable name you need to use for pictures, %VAR_pic2%, %VAR_photo%).
Add an Image Frame anywhere in the Scribus file («Scribus → Insert → Insert Image Frame») and open the dialog for getting an image (e.g. right click Image Frame → Get Image… on selected frame). Select the needed “placeholder” picture.
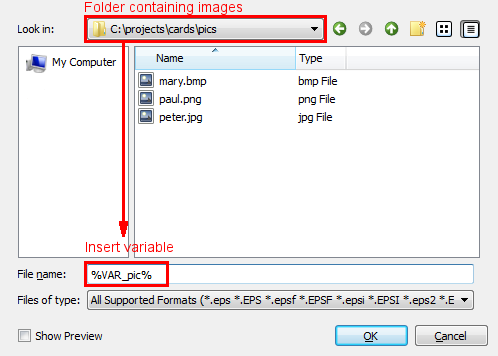
The images file can be defined just like any other variable described in earlier. There just has to be a column with a column-name corresponding to the variable-name in the Scribus template file. Just make sure to handle the file extension either in the file name, or in the CSV data, but not in both.
Importing vector images (SVG, PDF or other) as image frames does work in ScribusGenerator, just as with PNG or JPG images; just make sure your (relative or absolute) SVG file path matches the generator output directory, as that is the place Scribus will be looking from when transforming the SLA into your PDF format.
Scribus sometimes renders the included image in really low resolution, so you should check out the resolution (dpi) (and or size) or your source material. To quickly batch export SVG objects in multiple resolutions you may be interested in Inkscape’s object export script.
There is unfortunately no way to include dynamically vector files (pdf or svg) with ScribusGenerator, because of the way Scribus imports them (from the menu File > Import > Vector) by converting them one-the-fly to scribus objects. Which is great for direct editing in Scribus, but not for including external files by reference.
Dynamic Colors
Colors can be dynamically replaced just like text. See the screencast video @8:31, or simply
- edit the colors of your Scribus file (
edit > colours) and rename the colors you want to replace with variable names (typically replaceFromSVG#whateverwith the now well known form%VAR_name%). - define the colors you want to use in the final document, and use their Scribus names as values in your color data field.
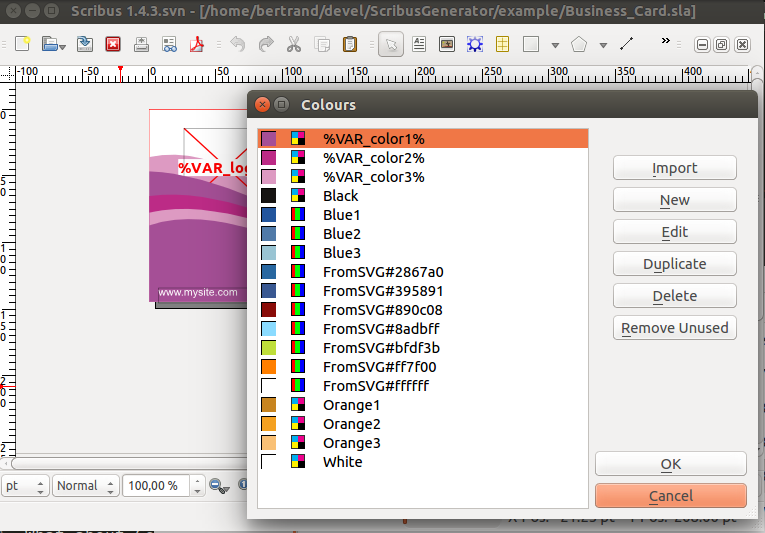
Use this together with the many renown color palettes directly included in Scribus to make your documents design rich and appealing !
Dynamic Links
A clickable (web)link can be inserted on nearly any scribus object in 2 steps:
right-click > PDF Options, activateIs PDF Annotationright-click > PDF Options > Annotation Properties, select typeExternal Web-Linkand enter the target url, where you can obviously use variables to be substituted too, as illustrated below.
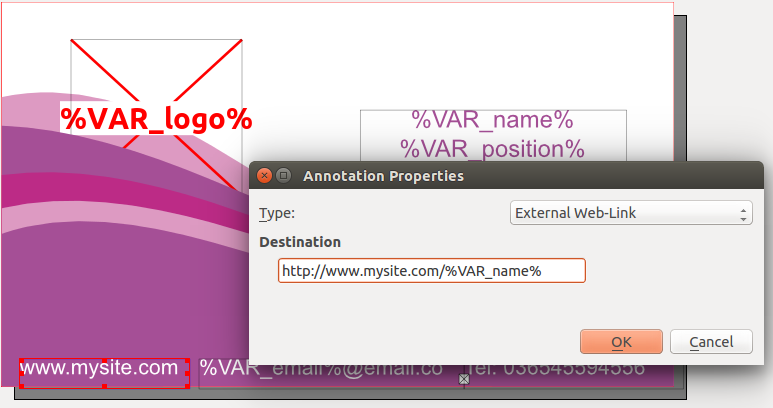
Merged output - single document
Instead of generating a single (sla or pdf) file for each data row, you can generate a single file that merges all these. Simply select the option accordingly to get the result illustrated below in a single Scribus (and/or pdf) file. If your document layout has multiple pages (double sided, or folded leaflet), it is important for Scribus Generator to be able to merge the files that your template has the same number of pages (or a multiple thereof). For instance, for a 3-fold document, your source sla should have 3, 6, or 9 pages (or any multiple of 3).

Multiple records on a single page
Scribus Generator allows you to display mupliple data entries in a single document. Great to generate your own listings, team charts, game cards, who’s who posters and more.
Simply drop the text %SG_NEXT-RECORD% in your document before each data entry except the first record, following our example document. Kindly note this token is case sensitive and must be upper-case. Scribus Generator will automatically load the next record as soon as it detects %SG_NEXT-RECORD%, and when it reaches the end of your template.
A full example to generate Monsters Game Cards based on Dungeon World is available in the MonsterCards directory, created by Dustin Andrews:

Advanced layout, groups and layers
The Scribus Generator script prioritizes items based on their Level in Scribus. For advanced layouts (groups, layers,…) we thus recommend to put your main item on the first level, together with the %SG_NEXT-RECORD% token before you group them together, for it to behave properly (assuming you call next record at the beginning of your 2nd item and next ones).
Changes in NEXT-RECORD syntax
Please note Scribus Generator v2.8 (from January 2019) changed the syntax of the “Next Record” feature to a less confusing name, as per suggestion #118
Update your older templates manually, changing %VAR_NEXT-RECORD% to %SG_NEXT-RECORD%, or all at once by calling, for instance:
python ./ConvertVAR_NEXT-RECORDToSG28.py ~/ScribusProjects/*/*.sla
Dynamic output file location
Scribus Generator allows you to customize the name (and location) of the generated document easily. Add the output file name you wish in your data, and use the corresponding variable (or combination of multiple variables) in the field “Output File Name”. Kindly note this file name is always relative to the output directory, and has no extension.
A dedicated variable %VAR_COUNT% can be used anywhere in the file output option that will be substituted with the position of the related data entry in the data file. Force that count figure to have a specific length by setting the OUTPUTCOUNT_FILL accordingly (only in Scribus 1.5.6+ version)
Have a look at the combination of values of parent and outfile in our example dataset and related example template.
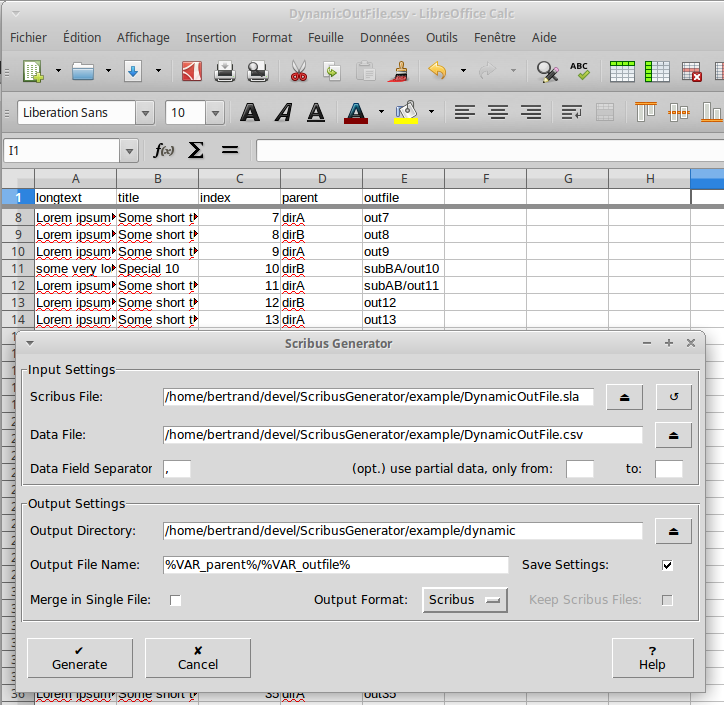
More advanced uses
Scribus Generator allows more tech-savvy users you to customize the generated documents even more, changing virtually any attribute of any object, such as the fill or outline color of a line, the color of some text, a line thickness, an object position,… See the screencast video @13:13.
For instance, to change dynamically the font of an object, add an attribute to it («righ-click on object → Attributes → Add »). The Parameter attribute must be set to SGAttribute, it’s name to the object property you want to change (in this case FONT) and its value to the desired dynamic value (typically some %VAR_name%). Your data (CSV) file should then contain the font name to use in the column of the given variable, such as “Arial Regular” or “Courier New Bold”.

To change the properties of a sub-element (such as one particular text line in a text frame), you may use the RelationshipTo field to define which sub-elements should receive the new property. Use * to modify all direct children, or any other simplified XPATH expression to modify only a subset.
Selected examples of SGAttributes:
| Name | Value | Parameter | RelationshipTo | Explanation |
|---|---|---|---|---|
FONT |
%VAR_font% |
SGAttribute |
//ITEXT[2] |
Font of the 2d text line in a frame, like “Arial Regular” |
FONTSIZE |
%VAR_size% |
SGAttribute |
//ITEXT |
Text size of all text lines in a frame, like “14” |
LINESP |
%VAR_spacing% |
SGAttribute |
//para[last()] |
Fixed line spacing of the last paragraph in a frame, like “9.5” |
YPOS |
%VAR_top% |
SGAttribute |
Margin from the top for vertical element position, like “22.04” | |
ROT |
%VAR_degrees% |
SGAttribute |
rotation of the current object, in degrees, [0 , 359] |
Please note ScribusGenerator does not create the attribute, but only looks to update its value. So you may need to slightly rotate the object (just put any value but 0 in the rotation box, it will be replaced anyway), to make sure the ROT attribute is indeed used by Scribus when saving the file.
Changes in SGAttribute syntax
Since ScribusGenerator v2.7 (released in April 2018), the syntax of the SGAttributes has been slightly changed to support Scribus 1.5.3. If you had templates written for an older version of the script kindly update your templates according to the documentation above.
This can be done using the classical Scribus Editors windows, simply moving your values of Parameter to RelationshipTo, and setting Parameter to SGAttribute.
If you have many such files, or attributes, a script is proposed to make this update automatically. Run it from the command line as follows, it creates automatically a backup of your old files:
python ./ConvertSGAttributesToSG27.py *.sla
Running Scribus Generator from the command line
It is possible to run Scribus Generator from the command line, and it’s fast! Great to automate your workflow or integrate with other tools.
Please note only the SLA generation works from the command line. PDF generation is at the moment not supported from the Scribus Generator command line.
Find all needed information from the script help: ./ScribusGeneratorCLI.py --help
positional arguments:
infiles SLA file(s) to use as template(s) for the generation,
wildcards are supported
optional arguments:
-h, --help show this help message and exit
-c DATAFILE, --dataFile DATAFILE
CSV/JSON file containing the data to substitute in each
template during generation. Default is scribus source
file(s) name with "csv" extension instead of "sla". If
csv file is not found, generation from this particular
template is skipped.
-d CSVDELIMITER, --csvDelimiter CSVDELIMITER
CSV field delimiter character. Default is comma: ","
-n OUTNAME, --outName OUTNAME
name of the generated files, with no extension.
Default is a simple incremental index. Using SG variables
is allowed to define the name of generated documents.
Use %VAR_COUNT% as a unique counter defined automatically
from the data entry position.
-o OUTDIR, --outDir OUTDIR
directory were generated files are stored. Default is
the directory of the scribus source file. outputDir
will be created if it does not exist.
-m, --merge, --single
generate a single output (SLA) file that combines all
data rows, for each source file.
-from FIRSTROW, --firstrow FIRSTROW
Starting row of data to merge (not counting the header
row), first row by default.
-to LASTROW, --lastrow LASTROW
Last row of data to merge (not counting the header
row), last row by default.
-s, --save Save current generator settings in (each) Scribus
input file(s).
-l, --load Load generator settings from (each) Scribus input
file(s). Overloads all default values, not provided
command line arguments.
requirements
This program requires Python 3.0+
examples:
ScribusGeneratorCLI.py my-template.sla
generates Scribus (SLA) files for each line of 'my-template.csv'
by substituting the provides values into 'my-template.sla' to the
current directory.
ScribusGeneratorCLI.py --outDir "/home/user/tmp" example/Business_Card.sla
generates Scribus files for each line of example/Business_Card.csv
in the "/home/user/tmp" subdirectory.
ScribusGeneratorCLI.py --outName "card-%VAR_COUNT%-%VAR_email%" */*.sla
generates Scribus files for each sla file in any subdirectory
that has a csv file with a similar name in the same directory.
Generated files will have a name constructed from the entry position
and "email" field, and are stored in their respective sla file directory.
ScribusGeneratorCLI.py --single -c translations.csv -n doc_ lang/*.sla
generates a single Scribus file for each sla file in the lang/ subdirectory
using all rows of the translations.csv data file.
Generated files will have a name constructed from the "doc_" prefix
and the input sla file name.
more information: https://github.com/berteh/ScribusGenerator/
More details
Clean output
Scribus Generator will remove unused variables from the generated documents, along with their containing text frame if that text frame contained nothing but variable(s).
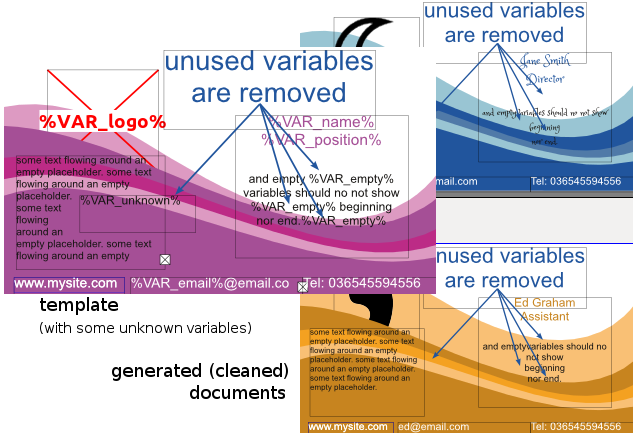
If you want to keep these unused variables and empty texts, simply change the default setting accordingly in ScribusGeneratorBackend.py, setting CLEAN_UNUSED_EMPTY_VARS to 0.
Similarly, if these unused variables or empty texts were preceded by a simple text (such as a single linefeed, or a character like any of ,;-), these list-like separators will be removed, so you can have a clean enumaration by appending your variables in a simple manner such as %VAR_n1%, %VAR_n2%, %VAR_n3%, %VAR_n4%., or in a more tabular layout using (single) linefeeds:
The following will show nicely even if some variable is empty or missing:
%VAR_n1%
%VAR_n2%
%VAR_n3%
%VAR_n4%
If you want to keep these separators, simply change the default setting accordingly in ScribusGeneratorBackend.py, setting REMOVE_CLEANED_ELEMENT_PREFIX to 0.
Linebreaks and tabulations in your csv data are replaced by the scribus equivalent (newlines and tabulations). To remove them and turning them to simple spaces set the setting KEEP_TAB_LINEBREAK to 0.
Logging and debug
ScribusGenerator records all its actions in a log file located (by default) in your user (home) directory. If you encounter an unexpected behaviour check out the content of .scribusGenerator.log to find out more. You can change the logging settings in logging.conf (see Python log configuration for more options).
Kindly copy-paste the relevant (usually last) lines of your .scribusGenerator.log if you want to report an issue.
Variable Names
Try to use plain word characters (A-Za-a0-9_) for variable names, with no whitespaces or other special characters (like ‘&’). E.g. use %VAR_first_name% and %VAR_zip_code% instead of %VAR_first name% and %VAR_&zip#code%. The columns of the data file (CSV) then would be first_name and zip_code.
This is only important for variable names in the scribus file and column names of the data file. The data FIELDS (the rows of the CVS) of course may contain ANY characters.
Database source
To use data from a database instead a (manual) spreadsheet you can simply export the related query result to a CSV file. Some examples below for common database engines. Find out more about using external data sources in our wiki .
Mysql:
mysql --delimiter="," -u myuser -p mydb -e "select f1,f2 from mytable" > /tmp/mydata.txt
or
mysql -u myuser -p mydatabase -e
"select field1 , field2 FROM mytable INTO OUTFILE
'/tmp/myfilename.csv' FIELDS TERMINATED BY ','
ENCLOSED BY '\"' LINES TERMINATED BY '\n' "
More over INTO OUTFILE at http://dev.mysql.com/doc/refman/5.1/en/select.html
Postgresql
toggle unaligned output with the \a switch, activate a comma as a separator with \f ,. Send output to a file with \o myfile.csv, then query your database.
Sqlite3
You can use sqlite3 -csv in command line or .mode csv in sqlite’s interactive shell
Scripts
Various scripts are available in the utils folder to facilitate your use of Scribus Generator.
Check out the related README !
Known Issues
Mac OSX/macOS troubleshooting
Some installs of Python on Mac OSX and macOS do not ship a working Tkinter package, that is required for regular ScribusGenerator GUI. Your options are to:
- Use the ScribusGeneratorMac script, which uses the Scribus Plugin API dialogs instead of Tkinter, or
- Find a way to setup a compliant TCL/Tk environment or
- Simply use the Scribus Generator command line interface script.
If you would like to improve the API dialog version or contribute another GUI to Scribus Generator that works on Macs don’t hesitate! Simply fork, branch, code and pull a request to get your contribution reviewed !
Support
Check out the wiki for more ideas, look at the solved and open issues, and then kindly report an issue online, and copy there the few last lines of your log file (it’s .scribusGenerator.log, inside your user (home) directory, to help find the reason of this bad behaviour, along with a short explanation of your problem.
Licence
The MIT License
Copyright
(c) 2011, Ekkehard Will (www.ekkehardwill.de)
(c) 2014-2024, Berteh (https://github.com/berteh/)
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
The software is provided “as is”, without warranty of any kind, express or implied, including but not limited to the warranties of merchantability, fitness for a particular purpose and noninfringement. In no event shall the authors or copyright holders be liable for any claim, damages or other liability, whether in an action of contract, tort or otherwise, arising from, out of or in connection with the software or the use or other dealing in the software.